
헤매어도 한 걸음씩
[논문 리뷰] RAPTOR: RECURSIVE ABSTRACTIVE PROCESSINGFOR TREE-ORGANIZED RETRIEVAL 본문
[논문 리뷰] RAPTOR: RECURSIVE ABSTRACTIVE PROCESSINGFOR TREE-ORGANIZED RETRIEVAL
ritz 2025. 1. 4. 22:06원문 : https://arxiv.org/html/2401.18059v1
소스코드 : https://github.com/parthsarthi03/raptor
RAG 파이프라인에 대해서 고민하던 중 지인의 추천으로 읽게 된 논문입니다.
RAPTOR 는 스탠포드 대학에서 제안한 RAG 방법론으로, 문서를 재귀적으로 요약하여 계층적인 트리 구조를 형성함으로써 장문의 문서에서의 RAG 성능을 향상시킬 수 있다는 가능성을 제시합니다. 본문에선 구체적인 설명에 앞서 RAPTOR 에 대해 간단히 소개한 후, Naive RAG 방식과의 차별점, 그리고 각 단계별로 어떤 이론이 사용되었는지 일부 소스코드와 함께 정리했습니다.
1. 기존 Naive RAG 방식과 RAPTOR 비교
Naive RAG :
Naive RAG 방식의 기본적은 흐름은 아래와 같습니다. 일반적으로 RAG는 크게 두 단계로 구성됩니다.
- Data Indexing
- 문서를 텍스트 청크로 분할하고, 이를 벡터화하여 Vector DB에 저장합니다.
- Data Retrieval & Generation
- 사용자의 질의를 벡터로 변환하고, Vector DB 에서 가장 유사한 상위 K개의 청크를 검색합니다.
- 검색된 청크를 LLM에 입력으로 제공하여 최종 응답을 생성합니다.

이 방식은 단순하고 효율적이지만, 긴 문서의 전체 맥락을 반영하거나 복잡한 질문에 성능이 떨어질 수 있습니다. (ex. 긴 문서에서 세부 정보와 전체 구조를 모두 고려해야 하는 질문에 대해선 상위 K개의 청크만으로 충분하지 않을 수 있음) 또 용량이 큰 문서의 경우 전체 토큰을 바로 LLM 에 넘겼을 때의 비용 문제에 대해서도 생각해볼 수 있습니다.
논문에서는 예시로 신데렐라 이야기를 언급합니다. "신데렐라가 어떻게 행복한 결말에 도달했는가?"라는 질문을 고려해 보면, Naive RAG 방식은 연속된 짧은 청크를 검색하기 때문에 이야기의 전체 맥락을 충분히 제공하지 못합니다. 단일 청크 단위로 Vector DB 에 저장되고, 질의에 대해 단순히 유사도가 높은 청크만 선택되기 때문입니다.
RAPTOR 소개 :
RAPTOR 는 텍스트를 청크 단위로 나누고 이를 임베딩 벡터로 표현한 뒤, 유사한 청크를 클러스터링하여 요약을 생성하고 이를 상위 노드로 통합하는 방식입니다. 이렇게 만들어진 트리 구조는 문서의 세부 정보(하위 노드)부터 전체적인 맥락(상위 노드)까지 다양한 추상화 수준의 정보를 포함합니다. 검색 시에는 사용자의 질문에 적합한 세부 수준의 정보를 트리 구조를 통해 효율적으로 찾아낼 수 있습니다.
- Tree construction
트리는 텍스트 청킹 및 임베딩 → 클러스터링 → 요약 과정을 반복하여 생성됩니다. (이 부분에 대해선 2. RAPTOR 방법론 부분에서 자세히 다뤄보겠습니다.)

- Leaf Layer : 문서를 100 토큰 단위로 분할하여 가장 하위 노드로 저장합니다. 이는 문서의 세부 정보를 나타냅니다.
- Clustering & Summarization : 유사한 청크를 그룹화한 후, 각 그룹 내 정보를 요약하여 상위 노드로 저장합니다.
- Root Layer: 최상위 노드로 문서 전체의 요약 정보를 포함하며 문서의 전반적인 맥락을 제공합니다.
- Retrieval
RAPTOR의 트리 구조에서는 모든 노드가 개별적으로 벡터화되어 저장되며, Retrieval 과정에서 모든 노드가 검색 대상이 됩니다. 이는 단순히 특정 청크를 검색하는 Naive RAG와 달리, 사용자의 질의에 따라 문서의 구조적 정보와 세부 정보를 동시에 활용할 수 있게 합니다. 이러한 방식은 문서의 맥락을 더 잘 반영하고, 긴 문서에 대한 검색 효율성을 높일 수 있습니다.
다음으론 RAPTOR 의 방법론 - 트리 구조 형성과 검색 방식에 대해서 구체적으로 다뤄보겠습니다.
2. RAPTOR Methods - Clustering Algorithm
RAPTOR의 트리 구조는 문서를 세부적인 정보에서 요약된 구조로 추상화하는, 아래의 프로세스 및 방법론을 사용하여 생성됩니다. 아래에서 3~5단계가 클러스터링 알고리즘의 주요 과정입니다.
1. 청크 생성
문서를 100 토큰 단위로 분할합니다. 문장이 100 토큰을 초과하는 경우 중간에서 자르지 않고 다음 청크로 이동하여 문장이 중간에 잘리지 않도록 합니다.
2. 임베딩 생성 : SBERT
각 청크는 SBERT(문장 BERT)를 사용하여 임베딩 벡터로 변환됩니다. 이 임베딩은 트리의 Leaf Layer를 형성합니다.
3. 클러스터링 : GMM
임베딩 벡터를 기반으로 RAPTOR는 Gaussian Mixture Models(GMM) 을 활용해 유사한 청크들을 클러스터링합니다. GMM은 데이터가 여러 가우시안 분포로부터 생성된다는 가정하에 데이터를 모델링하며, 각 텍스트 세그먼트(벡터)가 특정 분포에 속할 확률을 계산합니다. 이론적인 내용은 아래와 같습니다.
- 각 데이터 점 𝑥 가 𝑘-번째 가우시안 분포에 속할 확률은 아래와 같습니다. (여기서 μ𝑘 는 𝑘번째 가우시안 분포의 평균, 시그마 𝑘 는 𝑘번째 분포의 공분산 행렬 입니다.)

- 전체 데이터의 분포는 여러 가우시안 분포의 가중합으로 계산됩니다. (πk는 𝑘번째 가우시안 분포의 혼합 가중치 입니다.)
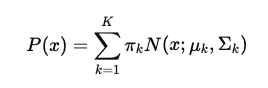
- 또 RAPTOR는 soft clustering 방식을 사용하여 하나의 텍스트 벡터가 여러 클러스터에 속할 수 있도록 유연하게 설정합니다.
- 클러스터링 과정에선 BIC(Bayesian Information Criterion) 를 사용하여 최적의 클러스터 수를 결정합니다. BIC는 모델의 적합성을 평가하며, 너무 복잡한 모델을 방지하기 위해 패널티를 적용합니다.
# get_optimal_clusters 로 최적 클러스터 수를 계산한 뒤 GMM 학습
# predict_proba를 사용해 각 데이터가 여러 클러스터에 속할 확률을 계산하고 soft clustering 구현
def GMM_cluster(embeddings: np.ndarray, threshold: float, random_state: int = 0):
n_clusters = get_optimal_clusters(embeddings)
gm = GaussianMixture(n_components=n_clusters, random_state=random_state)
gm.fit(embeddings)
probs = gm.predict_proba(embeddings)
labels = [np.where(prob > threshold)[0] for prob in probs]
return labels, n_clusters: GMM 은 soft clustering을 사용하여 데이터가 여러 클러스터에 걸쳐 속할 수 있도록 모델링합니다. 이는 텍스트 데이터처럼 복잡한 관계를 가진 데이터를 처리하는 데 적합합니다. 또한, 사용자가 설정한 threshold 값에 따라 확률이 높은 클러스터만 데이터에 할당되며, 이 값에 따라 클러스터링 결과가 크게 달라질 수 있습니다. 최적의 threshold 값을 자동으로 선택하는 알고리즘을 추가하는 것도 고려할 수 있을 것 같습니다.
다만 고차원 데이터에서 공분산 행렬 계산과 EM 알고리즘의 반복적인 계산으로 인해 비용이 크게 증가할 수 있을 것으로 보입니다. K-Means, DBSCAN, Hierarchical Clustering 등과 비교하여 확률 모델링 및 유연성 관점에서 성능 차이를 비교할 필요가 있습니다.
4. 차원 축소 : UMAP 활용
고차원 벡터 공간에서의 클러스터링 효율성을 높이기 위해 UMAP(Uniform Manifold Approximation and Projection)을 사용합니다. UMAP은 local 및 global 구조를 모두 보존하면서 차원을 축소합니다. 과정은 다음과 같습니다.
- 글로벌 클러스터를 식별 → 이후 글로벌 클러스터 내부에서 로컬 클러스터링 수행
이러한 클러스터링 프로세스는 광범위한 주제와 세부적인 관계를 모두 포착할 수 있습니다. 관련 소스코드는 아래와 같습니다.
def perform_clustering(
embeddings: np.ndarray, dim: int, threshold: float, verbose: bool = False
) -> List[np.ndarray]:
# Step 1: Global clustering (UMAP을 사용한 차원축소)
reduced_embeddings_global = global_cluster_embeddings(embeddings, dim)
global_clusters, n_global_clusters = GMM_cluster(
reduced_embeddings_global, threshold
)
# Step 2: Local clustering for each global cluster (노드 추출 및 그룹화)
node_clusters = []
for i in range(n_global_clusters):
cluster_nodes = [
embeddings[j]
for j in range(len(global_clusters))
if i in global_clusters[j]
]
if verbose:
print(f"Global Cluster {i} contains {len(cluster_nodes)} embeddings")
# 클러스터 크기 제한 및 재귀적 처리
if len(cluster_nodes) > threshold:
local_clusters = perform_clustering(
np.array(cluster_nodes), dim, threshold, verbose
)
node_clusters.extend(local_clusters)
else:
node_clusters.append(cluster_nodes)
return node_clusters: LLM의 토큰 한계를 고려하여 클러스터 크기를 제한하는 로직입니다. 너무 큰 클러스터로 인해 생기는 문제(ex. 요약 실패 emd) 를 방지하고, 대규모 문서에서도 안정성을 확보할 수 있습니다. 또 문서의 다층적 구조를 캡처하는 방식은 문맥을 잘 이해하는데 사용될 수 있습니다. 실제 적용시엔 Threshold, Recursive Depth 등에 따른 성능변화도 테스트해보면 좋을 것 같습니다.
5. 최적의 클러스터 수 결정 : Bayesian Information Criterion (BIC)
RAPTOR는 최적의 클러스터 수를 결정하기 위해 Bayesian Information Criterion (BIC)를 사용합니다. BIC는 모델의 복잡성을 패널티로 부여하여 적절한 모델을 선택합니다.

- N: 텍스트 세그먼트의 수
- 𝑘 : 모델 파라미터 수 (입력 벡터의 차원과 클러스터 수에 대한 함수)
- L^ : likelihood function 의 최댓값
BIC로 계산된 최적의 클러스터 수를 바탕으로 GMM의 파라미터(평균, 공분산, mixture weights)를 Expectation-Maximization (EM) 알고리즘을 사용해 추정합니다. 관련 소스코드는 아래와 같습니다.
# 여러 개의 클러스터 개수 𝑛에 대해 GMM을 학습하고, 각 𝑛에 대한 BIC 값을 계산
# BIC 값이 최소가 되는 𝑛을 선택하여 최적의 클러스터 수 반환
def get_optimal_clusters(
embeddings: np.ndarray, max_clusters: int = 50, random_state: int = RANDOM_SEED
) -> int:
max_clusters = min(max_clusters, len(embeddings))
n_clusters = np.arange(1, max_clusters)
bics = []
for n in n_clusters:
gm = GaussianMixture(n_components=n, random_state=random_state)
gm.fit(embeddings)
bics.append(gm.bic(embeddings))
optimal_clusters = n_clusters[np.argmin(bics)]
return optimal_clusters
: 최대 클러스터 수가 주어진 임베딩 데이터 수보다 큰 값이 되지 않도록 제한합니다. 클러스터 수를 점진적으로 변경하며 모델을 학습시키는데, 이는 데이터의 크기에 따라 max_clusters가 자동 조정됨으로서 소규모/대규모 데이터에서 모두 사용 가능합니다.
또 BIC 값을 통해 각 클러스터링 결과의 품질을 평가합니다. BIC 는 단순히 거리를 좁히는 것이 아닌, 모델의 복잡도를 고려하기 때문에 과소/과대적합을 방지할 수 있습니다.
6. 요약 생성 : LLM
클러스터링된 청크들은 GPT-3.5-turbo 모델을 사용하여 요약됩니다. 이렇게 생성된 요약된 텍스트는 트리의 상위 노드에 저장되며, 문서의 정보를 압축하지만 주요 맥락을 유지합니다.
7. 재귀적 반복 (트리 확장)
위 과정을 반복하며 클러스터링 → 요약 → 상위 노드 생성 작업을 수행합니다. 더 이상 클러스터링이 불가능할 때까지 반복하여 최종적으로 루트 노드가 생성됩니다. 만약 요약된 노드의 컨텍스트가 모델의 토큰 제한을 초과할 경우, 다시 클러스터링하여 트리를 확장합니다.
3. RAPTOR Methods - Querying
생성된 트리를 활용하여 정보를 검색할 때 2개의 쿼리 처리 방식을 제공합니다.

1. Tree Traversal (트리 탐색)
Tree Traversal 은 루트 노드에서 시작하여 사용자의 질의와 가장 관련성이 높은 노드를 선택하며 하위 레이어로 점진적으로 내려갑니다. (루트 노드와 질의 간의 유사도를 계산하여 가장 적합한 노드를 선택한 후, 해당 노드의 자식 노드들 간의 유사도를 다시 계산하는 과정을 반복)
예를 들어, "윤석열 탄핵에 대해 알려줘" 라는 질문을 하면, RAPTOR는 루트 노드에서 시작해 문서의 전체 주제를 탐색합니다. 먼저 "정치적 이슈"와 관련된 상위 노드를 찾고, 그 안에서 "윤석열 탄핵"과 관련된 하위 노드로 이동합니다. 이후 "헌법 위반", "정책 문제", "중립성 논란" 등 탄핵과 관련된 구체적인 정보를 제공할 수 있습니다.
이와 같은 방식으로 RAPTOR는 문서 구조를 따라 단계별로 관련 정보를 탐색하고, 사용자의 질문에 가장 적합한 세부 사항을 제공합니다.
2. Collapsed Tree (트리 평탄화)
Collapsed Tree 는 트리의 모든 노드를 단일 평면으로 변환한 후(=평탄화), 모든 노드에서 사용자 질의와 가장 관련성이 높은 N개의 노드를 직접 검색합니다. 트리 평탄화는 특정한 레벨의 추상화가 필요하지 않은 상황에서 빠르게 관련 정보를 검색할 수 있습니다.
비슷하게 "윤석열 탄핵에 대한 전체 요약을 알려줘"라는 질문을 한다면, RAPTOR는 Collapsed Tree(트리 평탄화) 방식을 사용해 트리 구조의 모든 노드를 단일 레이어로 평탄화합니다. 이후 모든 노드(루트, 중간, 리프)를 한꺼번에 비교하여 사용자 질문과 가장 관련성이 높은 k개의 노드를 선택합니다.
이 경우 "정치적 이슈"를 다루는 루트 노드와 "윤석열 탄핵"을 구체적으로 설명하는 중간 노드, 그리고 "헌법 위반", "정책 문제" 등을 포함한 리프 노드가 함께 검색 대상이 됩니다. RAPTOR는 이들 중 질문과 가장 유사한 노드를 선택해, "탄핵 논의의 배경과 핵심 사유"를 요약한 응답을 반환합니다.
Collapsed Tree 방식은 질문의 구체적인 수준과 상관없이, 전체 트리에서 가장 적합한 정보를 빠르게 제공한다는 장점이 있습니다. 예를 들어, 세부적인 레벨을 탐색하지 않고도 전체적인 요약이나 핵심 내용을 빠르게 얻고자 할 때 적합합니다.
정리하면 다음과 같습니다.
| 방법론 | 장점 | 단점 |
| Tree Traversal | 계층적 정보를 단계별로 탐색하여 세부적이고 맥락 있는 답변 제공 | 검색 속도가 트리의 깊이에 따라 느려질 수 있음 |
| Collapsed Tree | 모든 노드를 한 번에 탐색하여 빠르게 응답 가능 | 특정한 레벨의 세부 정보를 놓칠 가능성 존재 |
트리 탐색은 복잡한 질문이나 세부 정보를 요구하는 질의에 적합하며, 트리 평탄화는 단순하고 빠른 응답이 필요한 상황에서 유용합니다.
4. 성능 비교
논문에서는 다양한 실험을 통해 RAPTOR의 성능을 Naive RAG 방식과 비교/평가했습니다.
1. 데이터셋
Wikipedia와 PubMed와 같은 대규모 문서 데이터셋을 사용했습니다. 해당 데이터셋은 긴 문서와 복잡한 질의를 포함하고 있습니다.
2. 평가 지표
- Accuracy : 모델이 질의에 대해 적절한 응답을 제공하는지 평가합니다.
- Efficiency : RAPTOR가 Naive RAG 방식에 비해 응답 시간을 단축했는지 측정합니다.
3. 주요 실험 : Querying 방법 비교

- Tree Traversal: 서로 다른 top-k 값을 사용하여 성능 비교
- Collapsed Tree: 서로 다른 컨텍스트 길이(토큰 수)로 성능 평가
결과적으로 Collapsed Tree 방식이 2000 토큰을 사용했을 때 가장 우수한 결과를 나타냈으며, 이는 RAPTOR 의 주요 querying 전략으로 선택되었습니다.
3. 주요 실험 : Querying 예시

예시 질문 2개 :
- 이야기의 중심 주제는 무엇인가?
- 신데렐라는 어떻게 행복한 결말을 맞이했는가?
하이라이트된 노드는 RAPTOR가 선택한 노드이고, 화살표는 DPR(단순 Dense Passage Retrieval)이 선택한 리프 노드를 가리킵니다. RAPTOR는 DPR이 가져온 정보는 물론이고, 그보다 더 넓은 맥락이나 상위 요약까지 포함하는 경우가 많습니다. RAPTOR가 단순 검색 방식보다 훨씬 더 풍부하고 맥락에 맞는 답변을 줄 수 있다는 것을 보여주는 결과입니다!!!
개인적으로 재밌게 읽은 논문입니다. 초기 구축비용과 요약 품질에 대한 의존성을 잘 고려한다면, 장문의 문서에서 RAPTOR 가 좋은 접근법이 될 수 있을 것 같습니다. 이 글을 읽으셨다면, 원문도 읽어보시는 것을 추천드립니다!!!
또 확인해보니 LangChain 에서도 관련 테스트 코드를 제공하고 있어, 함께 확인해보시면 좋을 것 같습니다.
https://github.com/amrita-thakur/langchain/blob/main/RAPTOR.ipynb
langchain/RAPTOR.ipynb at main · amrita-thakur/langchain
Contribute to amrita-thakur/langchain development by creating an account on GitHub.
github.com



