

신용카드 서비스 이탈 여부를 예측하는 ML Model 개발
기존 고객 정보를 바탕으로, 고객의 이탈 여부를 예측하는 Machine Learning Model 개발
0. 분석 배경
이번 프로젝트에선 기존 고객 정보를 바탕으로 고객의 이탈 여부를 예측하는 Machine Learning Model을 개발했습니다.
이러한 예측이 중요한 이유는, 신규 고객 수를 확보하는데 드는 비용이 기존 고객을 유지하는 비용보다 훨씬 크기 때문입니다. 신규 고객을 확보하는 것에 천문학적 영업비용이 들고, 신규 카드 발급과 관련한 심사 비용 또한 무시할 수 없습니다. 많은 비용을 들여 획득한 고객이 이탈해 버릴 경우 이로 인한 손실은 막대합니다. 기존 고객의 이탈률을 낮출 경우 수익이 크게 개선될 것입니다.
따라서 기존 고객 중 이탈할 가능성이 높은 고객을 미리 알아내 막을 수 있다면, 그 효과는 더 많은 신규 고객을 확보하는 것보다 클 수 있습니다.
고객 이탈 여부를 정확히 예측하게 된다면 고객생애가치 (CLV: Customer Lifetime Value), 마케팅 투자 대비 수익 (Return on Marketing Investment) 등 또한 더 정확하게 계산할 수 있게 되고, 이것들은 결국 올바른 의사결정에 도움이 될 것입니다.
고객의 결정을 반대로 되돌릴 수 있도록 더 나은 서비스를 제공하고, 마케팅 비용과 노력을 최소화하여 이익을 극대화하기 위해 본 프로젝트를 진행하게 되었습니다.
1. 프로젝트 진행기간
- 2021.06.29 ~ 2021.07.02
2. 프로젝트 목표
- 기존 고객 정보를 바탕으로 고객의 이탈 여부를 예측하는 Machine Learning Model 개발
- ML Model을 분석하여 이탈 고객의 특성을 파악, 더 나은 서비스 제안
3. 진행 과정 및 세부사항
3-1. 데이터 선정 이유 및 문제 정의
- 분석 배경 및 프로젝트 목표에서 서술함
3-2. 가설 설정 및 평가지표 선택
- [가설 1] 연간 지출이 많을수록 고객 이탈률이 낮다.
- [가설 2] 비활성 상태인 달 수가 길수록 이탈률이 높다.
- Base line Model : Existing Customer

3-3. 데이터 전처리
이상치 확인

- Customer Age, Dependent count 등의 feature에 이상치가 있는 것 같아, 고윳값 확인을 통해 자세히 알아보겠습니다.
Age Span
[45 49 51 40 44 32 37 48 42 65 56 35 57 41 61 47 62 54 59 63 53 58 55 66
50 38 46 52 39 43 64 68 67 60 73 70 36 34 33 26 31 29 30 28 27]
Total Relationship Count
[5 6 4 3 2 1]
Income Span
['$60K - $80K' 'Less than $40K' '$80K - $120K' '$40K - $60K' '$120K +'
'Unknown']
Dependent count
[3 5 4 2 0 1]
Credit Limit
[12691. 8256. 3418. ... 5409. 5281. 10388.]- 고객의 나이, 보유 상품 수, 대출 한도 등의 최솟값/최댓값을 이상치로 처리하기는 어려워 그대로 사용하겠습니다.
3개 feature(Education_Level, Marital_Status, Income_Category)에 한해서 조사가 누락된 데이터(Unknown)가 존재합니다. 이를 다른 feature와의 상관관계를 통해 적절히 처리하겠습니다.
Attrition_Flag
Existing Customer 8500
Attrited Customer 1627
Name: Attrition_Flag, dtype: int64
Gender
F 5358
M 4769
Name: Gender, dtype: int64
Education_Level
Graduate 3128
High School 2013
Unknown 1519
Uneducated 1487
College 1013
Post-Graduate 516
Doctorate 451
Name: Education_Level, dtype: int64
Marital_Status
Married 4687
Single 3943
Unknown 749
Divorced 748
Name: Marital_Status, dtype: int64
Income_Category
Less than $40K 3561
$40K - $60K 1790
$80K - $120K 1535
$60K - $80K 1402
Unknown 1112
$120K + 727
Name: Income_Category, dtype: int64
Card_Category
Blue 9436
Silver 555
Gold 116
Platinum 20
Name: Card_Category, dtype: int64- 해당 feature에서 'Unknown'이 포함된 행이 겹치는지를 index를 통해 확인
----------Index of rows containing "Unknown" in Income_Category----------
Int64Index([ 19, 28, 39, 44, 58, 83, 94, 100, 101,
138,
...
9968, 9985, 10000, 10015, 10020, 10021, 10040, 10083, 10092,
10119],
dtype='int64', length=1112)
(1112, 20)
----------Index of rows containing "Unknown" in Education_Level----------
Int64Index([ 6, 11, 15, 17, 23, 24, 27, 30, 41,
50,
...
10041, 10046, 10071, 10082, 10089, 10090, 10094, 10095, 10118,
10123],
dtype='int64', length=1519)
(1519, 20)
----------Index of rows containing "Unknown" in Marital_Status----------
Int64Index([ 3, 7, 10, 13, 15, 26, 38, 55, 72,
81,
...
10015, 10020, 10038, 10064, 10066, 10070, 10100, 10101, 10118,
10125],
dtype='int64', length=749)
(749, 20)- 'Unknown'이 포함된 데이터가 총 3,046개로, 각 feature별로 1112, 1519, 749개씩 존재합니다.
- 이 중 334개의 row만 중복되며, 'Unknown'이 포함된 row가 대부분 겹치지 않는다고 볼 수 있습니다.
- 조사가 누락된 데이터(Unknown)를 포함한 row는 전체 데이터의 29.98%를 차지하며, 무시할 만큼 적지 않습니다.
- 따라서 완전히 제거할 경우 데이터의 손실, 편향이 일어날 수 있습니다.
- 다른 feature와의 상관관계를 확인하여 적절히 처리하겠습니다.

Income_Category 의 경우 Credit_limit과 뚜렷한 양적 상관관계(0.48)가 있습니다.
→ Credit_limit에 따라 Income_Category의 Unknown 데이터를 적절히 처리하겠습니다.
Education_Level 의 경우 딱히 상관관계를 갖는 feature를 찾을 수 없습니다.
Education_Level은 타겟과의 상관관계(0.001)도 매우 낮습니다.
→ 순서가 있는 feature이므로, mapping을 진행할 때 Unknown을 0으로 처리하겠습니다.
Marital_Status 의 경우 딱히 상관관계를 갖는 feature를 찾을 수 없습니다.
Marital_Status는 타겟과의 상관관계(-0.01)도 매우 낮습니다.
→ 순서가 없는 feature이므로 One-hot Encoding 후 Unknown feature를 drop처리 하겠습니다.
Credit_limit에 따라 Income_Category의 Unknown 데이터 처리
# Income_Category는 총 5개의 카테고리로 분류됩니다. 따라서 Credit_Limit도 5개의 그룹으로 나누겠습니다.
Data = data.copy()
# Credit_Limit을 5개의 category로 균등하게 배분 (카테고리의 크기순으로 라벨이 부여됩니다.)
Data['Credit_Limit_Group'] = pd.cut(Data['Credit_Limit'], 5, labels=['1', '2', '3', '4', '5'])
# Credit_Limit feature가 새로운 칼럼에 5개의 카테고리로 나뉜것을 확인할 수 있습니다.
Data['Credit_Limit_Group'].unique()['2', '1', '5', '4', '3']
Categories (5, object): ['1' < '2' < '3' < '4' < '5']
# Income_Category내 Unknown 데이터를, 5개의 카테고리로 나누어 맵핑
Data_unknown = Data[Data['Income_Category'].str.contains('Unknown')]
Data_Unknown = Data_unknown.copy()
Data_Unknown['Income_Category'] = Data_Unknown['Credit_Limit_Group']
Data_notunknown = Data[Data.Income_Category != 'Unknown']
Data = Data_Unknown.append([Data_notunknown])
Data.drop(['Credit_Limit_Group'],axis=1,inplace=True)
# Unknowm데이터가 맵핑 결과
Data.Income_Category.unique()array(['2', '1', '4', '5', '3', '$60K - $80K', 'Less than $40K', '$80K - $120K', '$40K - $60K', '$120K +'], dtype=object)
Income_Category feature내의 'unknown'데이터가 적절한 category(1~5)로 처리되었음을 확인
3-4. EDA, 데이터 시각화 및 분석 Data visualization&Analysis
- feature 간 상관계수 분석
- 상관관계가 높은 feature drop처리

- 타겟과 다른 feature간 상관계수 분석

타겟과 상관관계가 가장 높은 상위 2개 feature는
- Contacts_Count_12_mon : 지난 1년간 연락 횟수
- Months_Inactive_12_mon : 지난 1년간 비활성 상태인 달 수
입니다. 두 feature 모두 상관계수가 0.2 이하로, 약한 양적 선형 관계에 있다고 볼 수 있습니다.
festure별 분포 확인

Feature별 분포 관측 결과,
- Card_category 별로 불균형이 관측됩니다.
- 카드 등급별로 타겟과의 관계를 자세히 살펴보도록 하겠습니다.
- 연락 횟수별 신용카드 서비스 이탈률을 확인해보도록 하겠습니다.
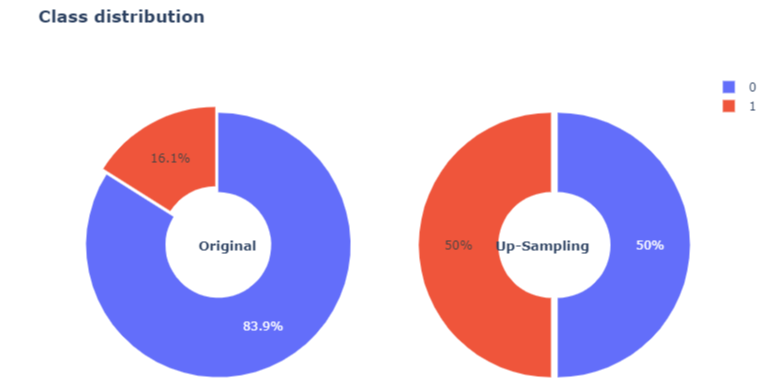
- Target variable의 불균형(imbalanced)을 확인할 수 있습니다. (1:16.1%, 0: 83.9%)
- 이 경우 모델은 minority group인 1의 경우를 무시하고 output을 0으로 예측합니다.
- 때문에 모델의 정확도는 83.9%가 되지만, 그것으로서의 역할을 전혀 하지 못합니다.
- 이를 Up-sampling or Down-sampling을 통해서 데이터의 imbalance를 해결하도록 하겠습니다.
- 보통 데이터가 많으면 많을수록 좋기 때문에 minority group의 양을 majority group의 양만큼 늘려주는 Up-sampling을 진행하도록 하겠습니다.
- 남성과 여성의 성별은 동등하게 분포되어 있습니다.
- 고객의 신용 카드 등급은 대부분 Blue입니다.
- 고객 대부분의 소득은 40,000K 미만입니다.
카드 등급별 분포
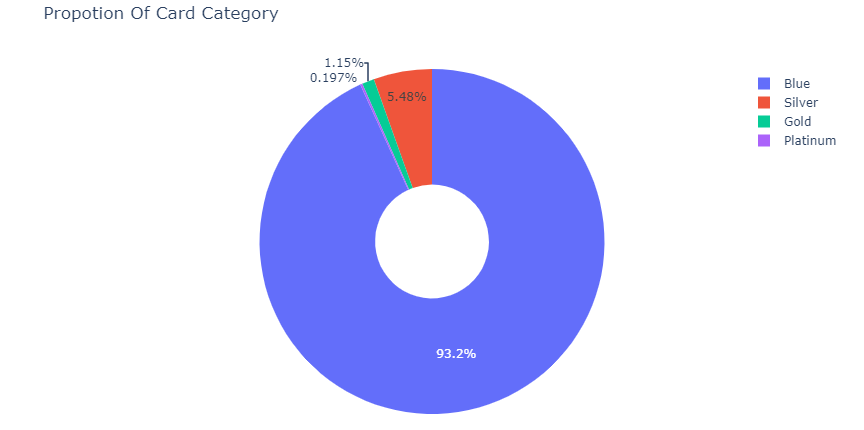
93%의 고객이 Blue 등급의 카드를 사용하고, 0.19%의 고객만이 Platinum 등급의 카드를 사용하고 있습니다.
더 자세히 살펴보기 위해, 카드 등급별 고객의 이탈률을 확인해보겠습니다.

카드 등급별 고객의 이탈률 확인 결과,
- Blue 카드 사용 고객의 이탈률이 16%로 가장 낮습니다.
- Blue 카드 사용 고객은 전체 고객 중 83.9%를 차지하기 때문에, 전체 데이터의 분포(이탈률 16.1%)와 비슷한 양상을 보이고 있습니다.
- Platinum 카드 사용 고객의 이탈률이 25%로 가장 높습니다.
- 카드 등급이 높아질수록 높은 이탈률을 보입니다.
다음으로, target과 가장 높은 상관관계를 보였던
feature인 Months_Inactive_12_mon(비활성 상태인 달 수), Contacts_Count_12_mon(연락 횟수)에 대해 분석해보겠습니다.

- 이탈 고객과 잔존 고객의 연락 횟수, 비활성 상태인 달 수가 비슷한 양상을 띄고 있습니다.
- 대부분의 비활성 개월은 2~3개월이며, 이는 지난 12개월 동안의 연락처 수와 비슷한 분포입니다.
- 각각의 feature별 이탈 고객과 잔존 고객의 비율을 파이 그래프를 통해 더 자세히 살펴보겠습니다.
비활성 상태인 달 수 (1~6) 별 이탈률 분포
지난 1년간 비활성 상태인 달 수 (1~6)별 고객의 서비스 이탈률 분포 확인

비활성 상태인 달 수 (1~6)별 고객의 서비스 이탈률 분포 확인 결과,
- 비활성 상태인 달 수 가 없을 때 가장 높은 이탈률(48.3%)을 보입니다.
- 비활성 상태인 달 수 가 1달~4달까지는 고객의 이탈률이 크게 증가하다가, 5달부터는 감소하는 추세를 보입니다.
- 비활성 상태인 달 수가 없거나, 비교적 적을수록 이탈률이 높습니다. 때문에 이 feature로 이탈 고객을 예측하는 데는 어려움이 있을 것 같습니다.
3-4. Up-Sampling
위에서 EDA를 진행하며 targe variable의 불균형(imbalanced)을 확인했습니다.
이를 해결하기 위해 Up-Sampling을 진행하겠습니다.
- Up-Sampling을 하기 전에 training/ test set을 나눠주어야 data leakage가 없습니다.
- Up-sampling은 minority class의 데이터를 복원 추출하여 늘리는 것이기 때문에, 다량의 training set을 학습하는 효과를 주는 것이 아닌 minority class의 특성을 반영한 데이터들이 늘어나게 됩니다.
- 모델이 test set의 분포를 학습하게 되면 data leakage 뿐만 아니라 over-fitting이 발생합니다.
- 위와 같은 이유로 training set에 한해 Up-Sampling을 진행하겠습니다.
# Separate data
target = 'Attrition_Flag'
train, test = train_test_split(df, train_size=0.8, test_size=0.2,
stratify=df[target], random_state=2)
train, val = train_test_split(train, train_size=0.8, test_size=0.2,
stratify=train[target], random_state=2)
train.shape, val.shape, test.shape
# ((6480, 16), (1621, 16), (2026, 16))# Target variable가 0인 경우: majority, 1인 경우 minority
train_majority = train[train.Attrition_Flag == 0]
train_minority = train[train.Attrition_Flag == 1]
train_majority.shape
# (5439, 16)from sklearn.utils import resample
# Resample function을 사용하여 minority를 majority 만큼 증가
train_minority_upsampled = resample(train_minority, replace=True, n_samples= train_majority.shape[0], random_state=2)
train_minority_upsampled.shape
# (5439, 16)# 증가시킨 minority dataframe과 majority dataframe을 concat
train_upsampled = pd.concat([train_majority, train_minority_upsampled])
train_upsampled.shape
# (10878, 16)# Resampel function으로 인해 데이터가 balanced 된것을 확인
train_upsampled.Attrition_Flag.value_counts()
Up-Sampling 후 클래스가 고르게 분포된 것을 확인할 수 있습니다.
3-5. 모델 비교 Modeling
3개 머신러닝 모델 적용 및 교차검증을 진행하여 성능을 비교합니다. 순서는 다음과 같습니다.
모델 1. RandomForestClassifier
모델 2. XGBoost Classifier
모델 3. LightGBM Classifier
# Separate the target feature from the training data
features = train_upsampled.drop(columns=target).columns
# Separate data
X_train = train_upsampled[features]
y_train = train_upsampled[target]
X_val = val[features]
y_val = val[target]
X_test = test[features]
y_test = test[target]
print(X_train.shape, X_val.shape, X_test.shape)
# (10878, 15) (1621, 15) (2026, 15)# Base line Model : 0 (Existing Customer)
print(train['Attrition_Flag'].value_counts(normalize=True))
print('\nBase line Model Accuracy: ', 0.839352)
- Base line Model : 0 (Existing Customer)
- 타겟의 최빈값인 0이 기준 모델이 됩니다.
모델 1. Randomforest Classifier
pipe_rf = make_pipeline(
StandardScaler(),
RandomForestClassifier(random_state=2))
pipe_rf.fit(X_train, y_train)
y_pred_rf = pipe_rf.predict(X_val)
print('Validation set Accruracy : ', round(pipe_rf.score(X_val, y_val),3))
print('F1 score :', round(f1_score(y_val, y_pred_rf),3))
# Validation set Accruracy : 0.919
# F1 score : 0.733모델1. RandomForestClassifier 의 하이퍼파라미터 튜닝 진행
dists_rf = {
'randomforestclassifier__n_estimators': stats.randint(50, 500),
'randomforestclassifier__max_depth': np.arange(10,20,1),
'randomforestclassifier__criterion': ['gini', 'entropy'],
'randomforestclassifier__min_samples_leaf': range(1, 30),
'randomforestclassifier__max_features': ['auto', 'sqrt']
}
clf = RandomizedSearchCV(
pipe_rf,
param_distributions=dists_rf,
n_iter=50,
cv=3,
scoring='f1',
verbose=1,
n_jobs=-1,
random_state=2
)
clf.fit(X_train, y_train);print('Optimal Hyperparameter : ', clf.best_params_)
# Optimal Hyperparameter : {'randomforestclassifier__criterion': 'entropy', 'randomforestclassifier__max_depth': 16, 'randomforestclassifier__max_features': 'auto', 'randomforestclassifier__min_samples_leaf': 2, 'randomforestclassifier__n_estimators': 108}# pipeline 생성 확인
pipe_rf.named_steps
#{'randomforestclassifier': RandomForestClassifier(random_state=2),
# 'standardscaler': StandardScaler()}pipe_rf = clf.best_estimator_
pipe_rf.fit(X_train, y_train)
y_pred_rf = pipe_rf.predict(X_val)
y_pred_proba_rf = pipe_rf.predict_proba(X_val)[:, -1]
print('AUC : ', round(roc_auc_score(y_val, y_pred_proba_rf),3))
print('f1-score : ', round(f1_score(y_val, y_pred_rf),3))
print("\nAccuracy: %.2f %%" % (accuracy_score(y_val, y_pred_rf)*100.0))
print("Recall: %.2f %%" % ((recall_score(y_val, y_pred_rf))*100.0))
print('\n',classification_report(y_val, y_pred_rf))
- 하이퍼파라미터 튜닝 후 f1-score가 0.733에서 0.734로 거의 차이가 없습니다.
- 또, 기준 모델인 0에 대한 정확도가 95%, 1에 대한 정확도가 74% 인 것으로 보아 Overfitting이 발생한 것으로 파악됩니다.
모델 2. XGBoost Classifier
바로 튜닝을 진행해보겠습니다.
# encode string class values as integers
label_encoded_y = LabelEncoder().fit_transform(y_train)
# grid search
model = XGBClassifier()
n_estimators = [50, 100, 150, 200, 500]
max_depth = [2, 4, 6, 8, 10]
objective = ['binary:logistic']
print(max_depth)
param_grid = dict(max_depth=max_depth,
n_estimators=n_estimators,
objective = objective)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model, param_grid,
scoring="neg_log_loss",
n_jobs=-1,
cv=kfold,
verbose=1)
grid_result = grid_search.fit(X_train, label_encoded_y)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
# plot results
scores = np.array(means).reshape(len(max_depth), len(n_estimators))
plt.figure(figsize=(8, 5))
sns.set_style("whitegrid")
for i, value in enumerate(max_depth):
plt.plot(n_estimators, scores[i], label='depth: ' + str(value))
plt.legend()
plt.xlabel('n_estimators')
plt.ylabel('Log Loss')

pipe_xg = grid_result.best_estimator_
pipe_xg.fit(X_train, y_train)
y_pred_xg = pipe_xg.predict(X_val)
y_pred_proba_xg = pipe_xg.predict_proba(X_val)[:, -1]
print('AUC : ', round(roc_auc_score(y_val, y_pred_proba_xg),3))
print('f1-score : ', round(f1_score(y_val, y_pred_xg),3))
print("\nAccuracy: %.2f %%" % (accuracy_score(y_val, y_pred_xg)*100.0))
print("Recall: %.2f %%" % ((recall_score(y_val, y_pred_xg))*100.0))
print('\n',classification_report(y_val, y_pred_xg))
모델 3. LightGBM Classifier
LightGBM은 XGBoost 보다 학습에 걸리는 시간도 훨씬 짧고, 메모리 사용량도 적은 모델입니다.
리프 중심 트리 분할 방식으로 트리의 균형을 맞추지 않고, 최대 손실 값을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지며 비대칭적인 규칙 트리가 생성됩니다.
이렇게 최대 손실값을 가지는 리프 노드를 지속적으로 분할해 생성된 규칙 트리는 학습을 반복합니다.
따라서 트리 분할 방식보다 예측 오류 손실을 최소화할 수 있다는 것이 LightGBM의 장점입니다.
import lightgbm as lgb
from lightgbm import LGBMClassifierpipe_lgb = make_pipeline(
LGBMClassifier(max_depth=5,
n_estimators=100,
learning_rate=0.2,
random_state=2)
)
pipe_lgb.fit(X_train, y_train)
y_pred_lgb = pipe_lgb.predict(X_val)
print('Validation set score : ', round(pipe_lgb.score(X_val, y_val),3))
print('F1 score :', round(f1_score(y_val, y_pred_lgb),3))
# Validation set score : 0.925
# F1 score : 0.781# 앞서 XGBoost와 동일하게 n_estimators는 400 설정.
lgbm_wrapper = LGBMClassifier(n_estimators=400)
# LightGBM도 XGBoost와 동일하게 조기 중단 가능
evals = [(X_val, y_val)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds=100, eval_metric="logloss",
eval_set=evals, verbose=True)
preds = lgbm_wrapper.predict(X_val)
pred_proba = lgbm_wrapper.predict_proba(X_val)[:, 1]. . .

early stopping으로 266회 반복 수행 후 학습을 종료했습니다.
best iteration : 166
이제 학습된 LighGBM모델을 기반으로 예측 성능을 평가해보겠습니다.
def get_clf_eval(y_val, pred=None, pred_proba=None):
accuracy = accuracy_score(y_val , pred)
precision = precision_score(y_val , pred)
recall = recall_score(y_val , pred)
f1 = f1_score(y_val,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_val, pred_proba)
print('Accuracy : {0:.3f}'.format(accuracy)),
print('Precision : {0:.3f}'.format(precision)),
print('Recall : {0:.3f}'.format(recall)),
print('\nf1-score : {0:.3f}'.format(f1)),
print('AUC : {0:.3f}'.format(roc_auc))get_clf_eval(y_val, preds, pred_proba)
LightGBM의 XGBoost 대비 장점
- XGBoost 대비 더 빠른 학습과 예측 수행 시간
- 더 적은 메모리 사용량
모델링을 진행하며 실제로 매우 빠른 속도를 실감할 수 있었습니다.
3-6. 모델 선택 및 모델 최적화 Model Selection and Model optimization
XGBoost Classifier는 Hyperparmeter 셋팅에 특히 민감합니다.
추가적으로 Hyperparmeter tunning을 진행하여 모델을 최적화하겠습니다.
XGBoost Classifier 를 GridSearchCv로 최적화한 Model2를 최종 모델로 선택하겠습니다.
XGBoost Classifier는 내부적으로 교차 검증을 수행하여 최적화된 반복 수행 횟수를 가질 수 있습니다.
또, 과적합 규제 (Regularization), 나무 가지치기 (Tree pruning), 조기 중단 (Early Stopping) 기능을 가지고 있습니다.
XGBoost Classifier의 Validation set에 대한 성능을 다시 한번 확인 후, 문제점을 파악하여 개선해보겠습니다.

AUC는 0.94로 높지만, precision과 recall 을 모두 반영한 f1-score의 점수가 0.72로 다소 좋지 않습니다.
기준 모델인
- 0의 정확도 : 0.97
- 1의 정확도 : 0.63
인 것으로 보아 Overfitting이 발생한 것으로 판단됩니다.
이때 모델에 추가된 새로운 tree의 가중치를 제어하는 학습률(Learning Rate)을 설정하여 Overfitting에 대한 문제를 개선할 수 있습니다.
최적의 학습률(Learning Rate)을 찾아 Overfitting을 해결해 보도록 하겠습니다.
# grid search
model = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model,
param_grid,
scoring="neg_log_loss",
n_jobs=-1,
cv=kfold)
grid_result = grid_search.fit(X_val, y_val)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
# plot
plt.figure(figsize=(7,5))
sns.set_style("whitegrid")
plt.errorbar(learning_rate, means, yerr=stds)
plt.title("XGBoost learning_rate vs Log Loss")
plt.xlabel('learning_rate')
plt.ylabel('Log Loss')
plt.show()
최적의 학습률은 0.1 입니다.
일반적으로 학습률이 낮을수록 더 많은 tree를 모델에 추가해야 합니다.
(학습률을 낮추게 되면 반대로 num_estimators는 높여줘야 합니다.)
tree 수가 증가함에 따라 학습 속도, 성능이 향상되고 안정될 것입니다.
최적의 학습률과 최적의 트리 수(n estimators)를 다시 알아보겠습니다.
# grid search
model = XGBClassifier()
# 학습률과 트리 수 최적화
n_estimators = [50, 100, 200, 300, 400, 500]
learning_rate = [0.001, 0.05, 0.01, 0.1, 0.2, 0.3, 0.5]
param_grid = dict(learning_rate=learning_rate, n_estimators=n_estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model,
param_grid,
scoring="neg_log_loss",
n_jobs=-1,
cv=kfold
)
grid_result = grid_search.fit(X_train, y_train)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
# plot results
scores = np.array(means).reshape(len(learning_rate), len(n_estimators))
plt.figure(figsize=(8, 5))
sns.set_style("whitegrid")
for i, value in enumerate(learning_rate):
plt.plot(n_estimators, scores[i], label='learning_rate: ' + str(value))
plt.xlabel('n_estimators')
plt.ylabel('Log Loss')
plt.savefig('n_estimators_vs_max_depth.png')

- learning_rate : 0.3
- n_estimators : 400
일 때 가장 좋은 성능을 보입니다.
최종 모델의 Validation set 정확도

- f1-score가 0.74로 조금 상승했습니다.
3-6. 최종 모델
최적의 Hyperparameter 값을 넣어 최종 모델을 생성합니다.
과적합 방지를 위해 max_depth, gamma값도 적절한 값으로 설정하겠습니다.
처음이자 마지막으로, Test set에서의 score를 확인해보겠습니다.

ROC curve
- AUC : 0.921
- f1-score : 0.687

좌측 상단에 수렴하는 형태의 ROC Curve입니다.
curve의 아래 부분 영역, 즉 AUC(Area Under Curve) 는 0.921로 1에 가까운 수치를 보이고 있습니다.
f-1 score는 0.69로 다소 낮습니다.
하지만 민감도와 특이도 모두 좋은 수치를 보이는 모델이고, 단순히 Acc가 높은 모델보다 훌륭한 모델이라고 할 수 있습니다.
3-7. Data Leakage 확인
k-fold cross validation을 이용하여 model의 validation score을 확인했습니다.
이 경우 전체 dataset에 Scaler를 적용하여 모델 학습을 하게 되면, cross validation안에서 train과 test set으로 구분되어지는 과정에서 data leakage가 발생합니다.
하지만 이번 프로젝트를 진행하며 모델의 학습 시 Scaler를 사용하지 않았고, test data에 대해서 처음이자 마지막으로 score를 확인했습니다.
또, over-sampling을 진행하기 전 데이터를 training, validation, test으로 나눈 후 training set에만 샘플링을 진행하였습니다.
때문에 데이터 누수가 발생했다고 볼 수 없습니다.
3-8. 모델 해석 Interpreting ML Model
Permutation Importance 확인
순열 중요도(Permutation Importance)는 기본 특성 중요도와 Drop-column 중요도 중간에 위치하는 특징을 가진다고 볼 수 있습니다.
Drop-column 중요도의 가장 큰 단점인 특성수만큼의 재학습을 안 하는 대신, 검증 셋에서 각 특성을 선택하여 해당 특성 값에만 무작위로 노이즈를 주고 예측합니다. 이때 그 특성의 중요도를 확인한 것이 Permutation Importance입니다.
re-training을 피하기 위해 test data에서만 진행하겠습니다.

permutation matrix는 각 feature가 shuffle 됨으로써 model의 performance가 얼마만큼 감소했는지를 보여줍니다.
감소한 크기가 클수록 feature는 model 학습에 중요한 요소입니다.
Total_Trans_Ct는 shuffle 됨으로써 model의 performance가 0.0542 만큼 감소했습니다.
이는 가장 큰 감소를 보여줌으로써, 모델 학습에 가장 중요한 요소라고 할 수 있습니다.
Feature selection
중요도를 이용하여 특성을 선택하겠습니다.
중요도가 – 인 특성을 제외해도 성능은 거의 영향이 없으며, 모델 학습 속도는 개선됩니다.
실제 프로젝트에선, 중요도가 낮은 특성을 제거(특성 선택) 후 최종 모델을 새로 정의하여 모델의 성능을 다시 확인했습니다.
성능 확인 결과, 특성 선택을 하기 전과 비슷한 성능을 보였으므로 이 부분에 대한 자세한 설명은 생략하겠습니다.
PDP
tree 기반의 모델은 함수 식을 통해 모델의 입력과 출력의 관계를 알 수 없습니다.
tree 기반의 모델은 information gain에 따라 sample들을 subgroup으로 나누는데 집중하기 때문입니다.
이때, 입력과 출력의 관계를 알아볼 수 있는 방법 중 하나가 Partial Dependence Plot입니다.
순열 중요도가 높은 상위 3개 feature에 한해서 PDP를 살펴보겠습니다.
(1) Total_Trans_Ct의 PDP
총 거래 횟수가 45회정도 될 때까지는 이탈률이 조금씩 증가하다가, 이후엔 45회~ 70회에선 첨차 감소하는 양상을 보입니다.
거래횟수가 70회 이상부턴 비슷한 이탈률을 유지하고 있습니다.

(2) Total_Relationship_Count의 PDP
고객의 보유 상품수가 3개일 때 까지 이탈률이 감소하다가, 그 이후엔 비슷한 정도를 유지합니다.

(3) Avg_Utilization_Ratio의 PDP
평균 카드 사용률이 0~10%대 까지는 고객의 카드 서비스 이탈률이 감소하다가, 이후엔 비슷하게 유지됩니다.

Shap value Plots
개별 예측 사례를 Shap value plot으로 시각화해보겠습니다.
Shap value plot을 분석함으로써 전체 모델을 해석할 수 있습니다.

- 고객의 이탈률을 예측하는데 가장 큰 영향을 준 feature는 Total_Trans_Ct이고, 그다음으로 큰 영향을 준 feature는 평균 카드 사용률입니다.
- 고객의 이탈률을 예측하는데 Negative 한 영향을 준 feature는 Dependent_count 등이 있습니다.
위의 결과를 요약하여, 아래와 같이 확인해볼 수 있습니다.

3-8. 고객 이탈률 감소를 위한 서비스 제안
1) 비활성 상태인 달 수 (1~6) 별 고객의 서비스 이탈률 분포 확인 결과
- 비활성 상태인 달 수 가 없을 때 가장 높은 이탈률(48.3%)을 보였습니다.
- 서비스를 이용 도중 비활성 상태인 달 수가 없이 바로 이탈했다는 것은, 타 카드사로 이동했을 가능성을 생각해볼 수 있습니다. 경쟁사보다 우위를 점하는 카드 서비스를 고려해봐야 할 것 같습니다.
2) 카드 등급이 높은 고객(Gold, Platinum)의 이탈률을 방지하는것이 매우 중요하다고 생각합니다.

카드등급이 Gold, Platinum인 고객은 전체 고객의 약 2%에 불과합니다.
하지만 충성고객을 확보하여 수익성을 높이는 일은 대부분의 기업에서 중요한 미션으로 자리 잡고 있습니다.
충성고객은 카드 사용액이 크고, 주변에 추천하여 긍정적 입소문을 퍼뜨립니다. 제품이나 서비스의 가격 인상에 민감하게 반응하지 않으며 더 많은 돈을 지불할지라도(카드 연회비) 저희 카드사를 선택했습니다.
해당 데이터로는 카드 등급별 카드 사용액에 대해서 구체적으로 알 수 없지만, 분명 그 액수는 2% 이상일 것이라고 예상됩니다.
따라서, 카드 등급이 높은 고객에 한하여 카드 사용 혜택을 늘리고, 상담 서비스나 은행 서비스에 대해 차별을 두며 이를 잘 홍보한다면 이탈률의 감소는 미미할 수도 있으나(고객의 차지 비율이 낮기에) 증가하는 수익성은 그보다 훨씬 클 것으로 예상됩니다.
이상으로 프로젝트를 마치겠습니다.
읽어주셔서 감사합니다🙂
Resources/References
1) Credit Card customers Dataset
캐글에 공개된 Credit Card customers 데이터셋을 사용하여 분석을 진행했습니다.
해당 데이터셋은 연령, 소득 수준, 혼인 여부, 신용카드 한도, 신용카드 카테고리 등을 포함한 약 10,000명의 고객 데이터로 구성되어 있습니다.
2) Reference
- Upsampling with SMOTE for Classification Projects
- Imbalanced Classes
- Handling Imbalanced Datasets
- Avoid Overfitting By Early Stopping With XGBoost
3) Keywords
- EDA, Data Preprocessing, Feature Engineering, Up-Sampling
- Randomforest Classifier, XGBoost Classifier, LightGBM Classifier, Cross Validation
- Model optimization, Data Leakage
- Permutation Importance, PDP, Shap
오류 지적 및 질문 환영합니다.
©해당 글에서 사용된 표지 이미지는 Adobe에서 구입한 이미지로, 무단으로 사용할 시 법적 처벌을 받을 수 있습니다.