
헤매어도 한 걸음씩
[논문 리뷰] CLSR: Disentangling Long and Short-Term Interests for Recommendation 본문
[논문 리뷰] CLSR: Disentangling Long and Short-Term Interests for Recommendation
ritz 2025. 3. 27. 14:10논문 링크 : https://arxiv.org/abs/2202.13090?utm_source=chatgpt.com
소스 코드 : https://github.com/tsinghua-fib-lab/clsr
최근 음악 스트리밍 서비스인 Spotify 를 처음 사용하게 되었는데요, 상황에 따라 달라지는 제 노래 취향을 반영한 추천 음악🎵 을 들으면서 Spotify 의 추천 알고리즘에 관심을 갖게 되었습니다. 저뿐만 아니라 많은 사용자들이 산책할 때, 업무 중일 때, 출퇴근길 등등 다양한 상황에서 서로 다른 음악을 듣는다는 점에서 이러한 상황 기반의 취향 변화를 추천 모델이 어떻게 학습하는지가 궁금해졌습니다. 해서 읽게 된 논문이 Variational User Modeling with Slow and Fast Features 입니다. Spotify 팀이 발표한 논문으로, 사용자의 느린(slow, 장기적인) 변화와 빠른(fast, 단기적인) 관심 변화를 각각 모델링하는 Variational Inference 기반 사용자 모델링 기법을 제안합니다. 다만 현재 진행 중인 인과추론 스터디의 목적과 더 부합하는 논문을 찾던 중, 비슷한 문제를 인과적으로 다루면서도 구현까지 가능한 CLSR: Disentangling Long and Short-Term Interests for Recommendation 논문을 리뷰하게 되었습니다.
CLSR은 대조 학습 기반의 자기 지도 방식으로 사용자의 장기적(long-term) 관심사와 단기적(short-term) 관심사를 명시적으로 분리하여 학습하는 프레임워크를 제안합니다. 수학적 깊이나 불확실성 모델링이라는 관점에서는 Variational UM 이 우위일 수 있지만 범용성, 모듈화 가능성, 실제 시스템 적용 관점에서는 CLSR이 더 강점이 있을 것으로 보입니다. 이번 리뷰에서는 CLSR 논문을 중심으로 살펴보되, 추후 Variational UM 논문과의 비교를 통해 두 접근 방식의 차이점과 장단점을 확인해 볼 예정입니다.
1. 개요
추천 시스템은 사용자 관심사를 정확히 모델링하기 위해 과거 상호작용 기록을 학습합니다. 이때, 사용자 관심사는 시간 축에 따라 서로 다른 두 성격을 가지게 됩니다.
- 장기 관심사 (Long-term interest): 비교적 안정적이며 사용자 선호의 전반적인 경향을 나타냅니다. (저는 평소에 잔잔한 팝송을 듣습니다. 장기 관심사는 이러한 사용자의 보다 일관된 취향을 의미합니다.)
- 단기 관심사 (Short-term interest): 최근 상호작용이나 일시적 상황에 민감하게 반응하는 동적 성격을 가집니다. (저는 운동할때 or 출근길엔 신나는 노래를 듣습니다. 단기 관심사는 이런 상황/시간에 따라 바뀌는 관심사입니다.)
기존 연구들은 장기 관심사와 단기 관심사를 명확히 구분하지 않고 통합적으로 모델링해 왔습니다. 하지만 이러한 방식은 추천의 정확도를 떨어뜨릴 뿐 아니라, 표현의 해석력을 낮춰 추천 근거를 설명하기 어렵게 만들고, 결과적으로 장기/단기 상황에 적절하게 대응하기 어려운 구조로 이어집니다. 또 두 관심사가 혼합될 경우, 표현 간 간섭이나 특정 행동에 대한 과도한 반응 등이 발생하여 추천 결과에 편향을 유발할 수 있는 문제도 존재합니다. CLSR은 이러한 한계를 극복하기 위해 다음과 같은 차별점을 제안합니다.
- 관심사 표현을 명시적으로 분리하는 dual-encoder 구조
- 자기 지도 대조 학습을 통해 라벨 없이도 표현 분리 학습
- 문맥에 따라 장단기 표현을 융합하는 attention 기반 fusion 모듈
정리하자면, CLSR은 기존 추천 알고리즘의 장/단기 관심사 간 간섭 문제를 해결하기 위해, 관심사를 명시적으로 분리(disentanglement)하고, 자기지도 학습(self-supervised learning)과 대조 학습(contrastive learning)을 활용한 구조를 제안하는 모델입니다.
2. 방법론
2.1 사용자 관심사 분리 모델링
CLSR은 전체 구조를 3가지 함수로 나눠서 설명합니다.

- 장기 관심사 표현 Long-term Interests Representation (f₁)
- 사용자가 지금까지 클릭하거나 구매한 전체 이력(시퀀스)을 기반으로 attention pooling을 적용해 장기 표현을 뽑습니다. 이 표현은 상대적으로 고정된 사용자 취향을 나타냅니다.
- 입력: 사용자 프로필(U) → 출력: 장기 표현(Uₗ)
- 단기 관심사 진화 Short-term Interests Evolution (f₂)
- GRU, Time4LSTM 등 순환 구조를 활용하여 최근 상호작용에 기반한 관심사 변화를 시계열적으로 모델링합니다. 즉, 지금 어떤 상황에 있는지를 반영하는 표현입니다.
- 이전 상태와 최근 클릭 아이템을 조합하여 단기 표현을 점진적으로 업데이트합니다. (= 직전 상호작용과 그 시점의 단기 표현을 바탕으로 현재의 단기 표현을 생성함)
- 입력: 이전 단기 표현, 과거 아이템, 과거 상호작용 → 출력: 현재 단기 표현(Uₛᵗ)
- 상호작용(행동) 예측 Interaction Prediction (f₃)
- 위에서 얻은 장기 표현과 단기 표현, 그리고 추천 후보 아이템을 함께 넣어서 MLP를 통해 행동을 예측합니다. (= 장기 관심사(Uₗ)와 현재 시점의 단기 관심사(Uₛᵗ), 그리고 대상 아이템(Vᵗ)을 바탕으로 사용자 행동 Yᵗ 예측)
- GRU 기반의 context vector, target item, 장단기 표현을 조합하여 attention 기반으로 융합합니다. 단순히 두 표현을 더하는 것이 아니라, attention을 통해 융합하는 것이 핵심입니다. 즉, 지금 상황에서 어떤 표현이 더 중요한지를 스스로 판단하게 합니다.
- 융합된 표현을 통해 MLP에서 사용자의 최종 행동(클릭, 구매 등)을 예측하게 됩니다.
아래는 이러한 사용자 관심사 분리 모델링을 나타낸 수식입니다. 한 줄짜리지만, 요 안에 CLSR의 구조가 전부 들어 있다고 볼 수 있습니다.

- 장기 관심사 𝑈ₗ은 전체 이력을 기반으로 추출합니다.
- 단기 관심사 𝑈ₛᵗ는 GRU 기반으로 이전 상태와 최근 상호작용에 따라 시계열적으로 변화합니다.
- 예측 시 두 관심사를 attention 기반 융합하여 최종 행동을 예측합니다. 이렇듯 위 수식은 시간의 흐름을 따른 구조를 보여준다고 볼 수 있습니다.
2.2 인코더와 표현 학습
앞서 설명한 것과 같이 CLSR은 사용자의 관심사를 두 가지 표현으로 나눕니다. 장기 관심사 표현과 단기 관심사 표현인데요, 각각을 학습하기 위해 별도의 인코더 구조를 사용합니다.
- 장기 인코더(φ): attention pooling 기반으로 전체 이력을 요약하여 사용자 선호를 안정적으로 표현합니다.
- 단기 인코더(ψ): GRU 기반 시퀀스 모델 위에 attention layer를 얹어 최근 상호작용의 순차적 패턴을 반영합니다.
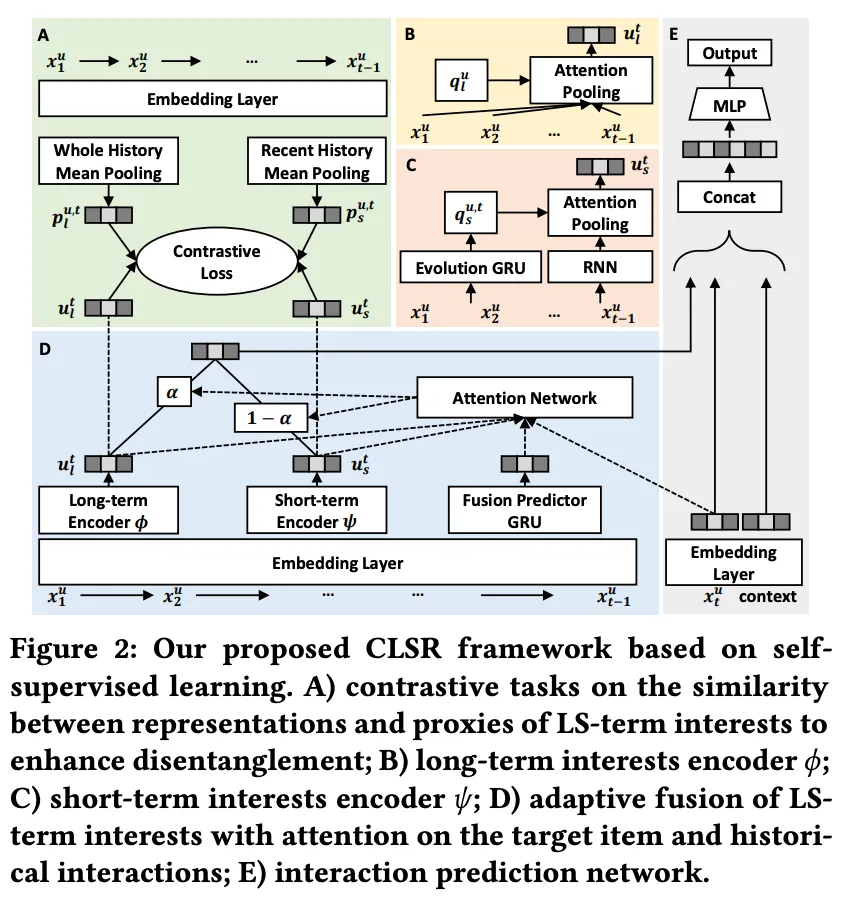
A. Contrastive Tasks
그림의 좌측 초록색 영역입니다. 이 부분은 CLSR에서 가장 중요한 표현 분리(disentanglement)를 담당합니다.
CLSR은 라벨 없이도 장단기 관심사를 명확히 분리할 수 있도록 프록시(proxy) 를 생성합니다.
- 장기 프록시 𝑝ₗ : 전체 이력의 평균 임베딩
- 단기 프록시 𝑝ₛ : 최근 k개의 상호작용 평균 임베딩
이 프록시들은 각각 "이런 게 장기적인 관심사의 대표적인 모습이야" 또는 "이런 게 최근 관심사야" 라고 알려주는 지도 신호 역할을 합니다. 즉, 명시적인 라벨이 없어도 각 표현이 어떤 관심사에 대응하는지를 자기 지도 방식으로 학습할 수 있도록 유도합니다. 이러한 대조 학습의 목적은 아래 2개 인코더를 출력하는 데 있습니다.
- 𝑢ₗ: 장기 인코더(φ)의 출력 (사용자의 장기 관심사 표현)
- 𝑢ₛ: 단기 인코더(ψ)의 출력 (사용자의 단기 관심사 표현)
관심사 표현(𝑢ₗ, 𝑢ₛ)과 프록시(𝑝ₗ, 𝑝ₛ) 간의 유사도를 기반으로 아래와 같이 대조 학습을 적용하고, Triplet Loss 또는 BPR Loss를 통해 학습합니다. (두 손실함수에 대해선 2.3 에서 다뤄보겠습니다.)
- 𝑢ₗ (장기 표현)은 𝑝ₗ (장기 프록시)와 가깝게, 𝑝ₛ(단기 프록시) 와는 멀게 학습
- 𝑢ₛ (단기 표현)은 𝑝ₛ(단기 프록시)와 가깝게, 𝑝ₗ(단기 프록시) 와는 멀게 학습
이를 통해 장기 표현과 단기 표현이 서로 간섭 없이 독립적으로 학습되도록 설계되었습니다.
B. Long-term Encoder (φ)
- 전체 시퀀스에 attention을 적용하여 장기 관심사 표현 𝑢ₗ을 생성합니다. 사용자의 일관적인, 전반적인 선호를 반영하는 안정적인 표현입니다.
C. Short-term Encoder (ψ)
- GRU 기반 시퀀스를 바탕으로 시점 t에서의 단기 관심사 표현 𝑢ₛᵗ를 생성합니다. 이 표현은 "지금 이 순간, 이 사용자가 어떤 걸 원하고 있는지"를 나타냅니다.
D. Adaptive Fusion Module
- 그냥 더하는 것이 아닌, target item과 두 표현 간의 유사도를 attention으로 비교해서 가중치 α 를 학습합니다.
최종 표현은 다음과 같이 계산되는데요, 즉 현재 상황이 장기 취향에 더 가까우면 α가 커지고, 최근 맥락이 더 중요하면 (1−α) 가 커지는 식입니다. 이 융합 모듈로 인해 CLSR은 사용자 문맥에 따라 유연하게 표현을 조합할 수 있게 됩니다.

E. Interaction Prediction (=추천 예측 모듈)
우측 회색 박스 영역입니다. CLSR에서 학습된 장기 표현 𝑢ₗ 과 단기 표현 𝑢ₛ 은 최종적으로 융합(fusion)되어 추천 예측에 활용되며, 아래와 같은 두 단계로 구성됩니다.
1. 융합 가중치 𝛼 계산
CLSR은 attention 기반 융합 가중치 𝛼 를 학습하여, 현재 상황에서 장/단기 표현 중 어느 쪽이 더 중요한지 결정합니다.
입력 요소 :
- 𝑢ₗ (장기 관심사 표현)
- 𝑢ₛ (단기 관심사 표현)
- Target item embedding (추천할 아이템의 임베딩)
- 과거 시퀀스 (사용자의 이전 행동 데이터)
Attention Mechanism :
Target item embedding과 장단기 표현의 유사도를 비교하여 𝛼 를 학습하고, 이를 통해 사용자의 현재 상태에 따라 장기/단기 표현의 비율을 조정합니다. 예를 들어,
- 반복 탐색(같은 카테고리 아이템 탐색 중) → 장기 표현( 𝑢ₗᵗ ) 비중 증가 (𝛼 ↑ )
- 새로운 카테고리 탐색 중 → 단기 표현( 𝑢ₛᵗ) 비중 증가 (1 - 𝛼 ↑ )
2. 최종 사용자 표현(𝑢ᵗ) 생성
융합된 최종 사용자 표현은 아래와 같이 계산됩니다.

𝛼 가 클수록 장기 관심사 반영이 증가하며, 1−𝛼 가 클수록 단기 관심사 반영이 증가합니다. 즉, CLSR은 고정된 비율이 아니라, 문맥(Context)에 따라 장기/단기 표현의 중요도를 동적으로 조절할 수 있도록 설계되어 있습니다. 이러한 구조를 통해 CLSR은 단순한 표현 결합이 아닌, 시간 축에 따른 관심사의 이질성과 독립성을 고려한 표현 학습과 예측 과정을 설계할 수 있게 됩니다.
요약하면,
- 장기 표현은 전체 이력 기반으로,
- 단기 표현은 최근 행동 흐름 기반으로 학습되며,
- 이 둘은 대조 학습을 통해 명확히 분리되고,
- 마지막엔 상황에 맞춰 융합해서 예측에 활용되는 방식입니다.
2.3 대조 학습을 통한 분리 - 손실함수
2.2 에서 설명한 바와 같이 관심사 표현(𝑢ₗ, 𝑢ₛ)과 프록시(𝑝ₗ, 𝑝ₛ) 는 아래와 같은 총 4개의 대조 관계를 설정하고, Triplet Loss 또는 BPR Loss를 통해 학습합니다.
| 인코더 출력 | Positive (유사해야 함) | Negative (멀어야 함) |
| 𝑢ₗ | 𝑝ₗ | 𝑝ₛ |
| 𝑢ₛ | 𝑝ₛ | 𝑝ₗ |

각 손실 함수에 대한 구성은 아래와 같습니다.
1. Triplet Loss (삼중항 손실):

- a: anchor (예: 𝑢ₗ)
- p : positive (예: 𝑝ₗ)
- n : negative (예: 𝑝ₛ)
- ϵ : margin (안전 거리)
Triplet Loss는 a 에 대해, p는 더 가깝게, n은 더 멀게 학습하도록 만드는 손실 함수입니다. 즉, 표현 간의 상대적인 유사도 차이를 학습하는 데 사용됩니다. (+두 유사도 차이가 최소 ϵ 이상은 나도록 강제) 이러한 구조는 표현 사이의 상대적 유사도 차이를 학습하게 합니다. 비유해서 설명하자면 "내(Anchor)가 좋아하는 음악(𝑝ₗ)과 최근 친구가 들려준 음악(𝑝ₛ)이 있을 때, 나의 장기 취향 표현(𝑢ₗ)은 내 원래 취향(𝑝ₗ)에 더 가깝고, 최근 유행(𝑝ₛ)과는 일정 거리 이상 떨어져 있어야 한다" 로 볼 수 있습니다.
2. BPR 손실:

BPR Loss는 추천 시스템에서 pairwise ranking을 학습할 때 쓰이는 손실 함수입니다. 작동원리로는 모델이 anchor와 positive의 유사도가 anchor와 negative의 유사도보다 크도록 학습하게 만듭니다. (시그모이드 안의 값이 클수록 손실이 작아지므로, positive가 negative보다 충분히 유사하면 loss는 거의 0에 가까워짐)
논문에서는 두 방식 모두 실험하였으며, Triplet loss가 표현 분리와 예측 성능에서 더 좋은 결과를 보였다고 합니다.
3. 전체 대조 손실:
최종 대조 손실은 위 네 가지 관계를 모두 포함한 합산 형태로 정의됩니다.

각 인코더가 자신의 관심사 표현에 집중하고, 다른 표현으로부터 분리되도록 유도합니다. 결과적으로 장기와 단기 표현이 편향 없이, 상호 간섭 없이, 명확히 분리된 구조로 학습됩니다.
이렇듯 프록시 기반의 대조 학습은 CLSR이 라벨 없이도 관심사를 분리할 수 있도록 해주는 핵심 메커니즘입니다. 표현 간 유사도와 거리의 대조를 통해 인코더가 자신이 담당한 관심사에만 집중하게 만들 수 있습니다. 이러한 대조학습이 필요한 이유로는, 장기 표현이 단기 프록시와도 유사해진다면 표현이 섞이게 되며 이는 행동의 원인 분석을 어렵게 만들기 때문입니다. 즉 4개 방향의 대조 관계 설정은 표현 간 간섭(interference)을 방지하는 기제가 됩니다,
3. 실험 결과 및 인과 분석
CLSR은 Taobao(이커머스)와 Kuaishou(숏폼 비디오) 두 실제 대규모 데이터셋에서 평가되었으며, 기존 추천 모델 대비 의미 있는 성능 향상과 인과적 해석 가능성을 동시에 입증합니다. 주요 분석은 아래의 일곱 가지로 구성됩니다.
3.1 단일 표현 성능 비교 (One-side Interests)
CLSR은 장기와 단기 표현을 명시적으로 분리하여 학습하므로, 각 표현이 단독으로도 유효한지를 확인하는 것이 중요합니다. 이를 위해 CLSR과 비교 모델(SLi-Rec)에 대해 다음 세 가지 설정에서 AUC를 측정했습니다.
- 장기 표현만 사용
- 단기 표현만 사용
- 장기 + 단기 표현 결합

- CLSR은 단기 또는 장기 표현 하나만 사용해도 SLi-Rec의 결합 표현보다 더 높은 AUC를 기록했습니다.
- 특히 단기 표현만 사용했을 때 Kuaishou에서 약 0.1 이상의 성능 차이를 보입니다.
- 이는 CLSR이 표현을 효과적으로 분리해 각 표현이 독립적으로도 강력한 성능을 가지도록 설계되었음을 시사합니다.
3.2 반사실 평가 (Counterfactual Evaluation)

CLSR의 장단기 표현이 각각 독립된 인과 요인으로 작동하는지를 검증하기 위해 반사실 실험을 수행했습니다. (표현 학습에 인위적 간섭(intervention)을 가한 실험을 설계) 여기서는 두 가지 간섭(intervention) 시나리오를 설정합니다.
- Shuffle: 시퀀스의 순서를 무작위로 섞어 단기 정보 제거
- Truncate: 초기 이력을 제거하여 장기 정보 약화
→ Figure 4는 이러한 세 가지 시나리오(factual, shuffle, truncate)의 차이를 나타냅니다.
결과적으로 Shuffle에서는 단기 표현의 성능이 하락했고, Truncate에서는 장기 표현 성능이 저하됐습니다. 즉, shuffle 실험에서 단기 표현 기반 예측 성능이 급감한 것은 단기 요인이 제거되었기 때문이며, truncate 실험에서는 장기 표현 기반 성능이 하락함으로써 장기 요인이 제거되었음을 보여줍니다. 이는 CLSR이 실제로 관심사 표현을 성공적으로 분리했음을 보여줍니다. (= 인과적 독립성 검증 근거)
정리하자면, CLSR 표현이 각 관심사 정보에만 민감하게 반응함을 확인함으로써 인과적 독립성을 간접적으로 검증했다고 볼 수 있습니다.
3.3 Truncate 실험
시퀀스 길이에 따라 성능이 어떻게 바뀌는지 실험한 부분입니다.

시퀀스의 길이를 조금씩 늘려가며 예측 성능 변화를 측정했습니다. 이 실험을 통해 장기 표현이 충분한 이력에 의존하는지, 단기 표현은 상대적으로 짧은 문맥에 기반하는지를 확인할 수 있습니다.
- Figure 5(a)는 CLSR 전체 모델 기준으로, 시퀀스 길이가 길어질수록 AUC가 상승함
- Figure 5(b)는 장기 표현만 사용한 경우로, 짧은 이력에서는 낮은 성능, 긴 이력일수록 성능 증가
→ CLSR이 시간 축 기반 관심사(표현) 분리에 성공했음을 의미합니다.
3.4 대조 학습 효과 분석 (Ablation & Hyperparameter Study)

CLSR은 자기 지도 방식의 대조 학습을 통해 표현을 분리합니다. 이 구성 요소가 성능에 기여하는지를 확인하기 위해 다음 실험을 진행했습니다.
- CLSR에서 대조 손실을 제거한 ablation 실험
- 기존 모델(DIEN)에 CLSR의 대조 학습만 적용한 실험
- 대조 손실 가중치(β)의 변화에 따른 민감도 실험
Figure 6(a) 에서 알 수 있듯이, 대조 손실 제거 시 GAUC가 0.01 이상 감소했습니다. 이는 표현 분리에 contrastive loss가 핵심적으로 기여함을 보여줍니다. 또 Figure 6(b) 에서 β가 너무 크거나 작을 경우 분리도와 정확도 모두 하락함을 보여, 최적의 β=0.1 에서 가장 좋은 성능을 보임을 확인했습니다. 이 실험은 대조 학습이 표현 분리와 예측 성능 향상에 모두 중요하다는 것을 보여줍니다. 단순한 장단기 분리 구조만으로는 부족하고, self-supervised 대조 신호가 핵심적인 부분임을 증명했습니다.
3.5 융합 전략 비교 (Adaptive vs Fixed Fusion)
이번엔 장단기 표현을 어떻게 융합하느냐에 따라 성능이 달라지는지를 확인한 실험입니다.
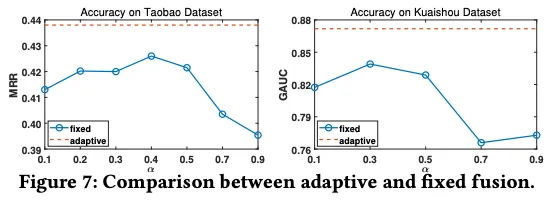
표현 융합 시 attention 기반으로 가중치 α를 동적으로 조절하는 adaptive fusion이 고정 가중치 방식보다 우수한지 실험했습니다.
- Adaptive 방식: attention 기반으로 α를 동적으로 조절
- Fixed 방식: α를 0.1 ~ 0.9로 고정해서 실험
Figure 7은 Adaptive 방식이 모든 fixed 방식보다 성능이 좋음을 보여줍니다. 특히 장/단기 비중이 바뀌는 컨텍스트에서는 큰 차이가 발생했습니다. 사용자의 문맥에 따라 장단기 표현의 중요도를 유연하게 조절하는 구조가 실제로 성능 향상에 기여함을 보여줍니다.
3.6 관심사에 따른 인과적 예측 전략
CLSR이 실제 사용자 행동(클릭 vs. 구매/좋아요)에서 장기 및 단기 관심사를 다르게 반영하는지 확인하는 실험입니다. 실제 예측 태스크(예: 클릭 vs 구매)에서도 관심사의 중요도를 인과적 방식으로 반영했습니다.
1. 사용자 행동 유형을 구분
- 클릭(Click): 순간적인 관심을 반영하는 이벤트
- 구매(Purchase)/좋아요(Like): 장기적인 관심과 강한 선호를 반영하는 이벤트
2. 각 행동 유형에 대해 CLSR의 예측 성능을 분석
- 클릭 예측 시: 단기 표현이 중요한지 확인
- 구매/좋아요 예측 시: 장기 표현이 중요한지 확인
→ 이를 이전 모델(SLi-Rec) 대비 CLSR이 관심사 전환을 더 잘 반영하는지 비교했습니다.
결과적으로 CLSR은 이러한 구조를 내부적으로 반영하여 상황에 따라 attention 비중을 조절함을 보입니다.
- 클릭 예측 시, CLSR은 단기 표현을 더 활용
- 클릭 예측 성능(AUC 기준)이 SLi-Rec 대비 3~9% 증가 (=CLSR이 최근 관심사를 더 잘 반영했기 때문)
구매/좋아요 예측 시, CLSR은 장기 표현을 더 활용
- 장기 표현 기반 예측 성능이 SLi-Rec보다 높음
- 특히, 사용자 히스토리가 긴 경우 성능 향상 폭이 더 큼
→ CLSR이 단순한 표현 결합을 넘어서 인과적 행동 예측 구조를 갖추고 있음을 보여줍니다.
3.7 실험 결과 요약 및 성능 정리
CLSR은 실험 전반에 걸쳐 다음을 보입니다.
- 정확도 향상: AUC 0.01~0.03 개선, NDCG 최대 5% 개선
- 표현 분리 성공: 장기/단기 표현 단독 사용 시에도 우수한 성능 확보
- 인과적 독립성 확보: Shuffle/Truncate 간섭 실험에서 표현이 해당 요인에만 반응함
- 융합 적응성: attention 기반 fusion이 고정 가중치보다 우수
- 인과적 행동 분화: 클릭 vs 구매 예측 시 표현 선택이 다름
4. 인과적 관점에서의 CLSR
4.1 인과 요인의 분리
사용자 행동은 두 개의 독립 인과 요인인 장기 관심사와 단기 관심사의 결합으로 나타납니다. CLSR은 별도의 인코더를 통해 이들을 분리하여 표현함으로써, 잠재 요인의 인과적 구분을 실현했습니다.
4.2 교란(confounding) 제거
상호작용 이력은 장단기 관심사 모두에 영향을 미칠 수 있는 공통 원인(confounder)입니다. CLSR은 프록시 기반 대조 학습을 통해 각 표현이 해당 관심사에 집중하도록 유도, 불필요한 교란을 제한했습니다.
4.3 반사실 평가를 통한 인과 검증
- shuffle: 순서를 무작위로 섞어 단기 정보 제거 → 단기 표현 기반 예측 성능 급감
- truncate: 초반 이력 제거 → 장기 표현 기반 예측 성능 급감
각 표현이 해당 요인에만 민감하게 반응함을 입증함으로써, 인과적 독립성의 간접적 근거가 될 수 있습니다.
4.4 표현 간 편향 제거
단기 표현에 장기 정보가 섞이거나 반대의 경우가 발생하면 표현 편향(bias) 발생합니다. CLSR은 각 표현이 대응된 관심사만을 반영하도록 훈련하여 표현 간 간섭을 차단했습니다.
5. 시사점 및 결론
5.1 CLSR의 한계 및 개선점
- 관심사 프록시의 단순한 평균 기반 설계는 표현의 품질에 영향을 줄 수 있습니다.
- 예시로, 평균 임베딩은 사용자의 반복적 행동이나 특이한 소비 패턴을 제대로 반영하지 못할 수 있음
- 향후에는 사용자 특성에 따라 가중치를 다르게 주거나, attention 기반 프록시 생성 기법을 적용해 볼 수 있음
- 사용자 cold-start 문제에 대한 고려가 부족합니다.
- CLSR은 충분한 이력 기반으로 장단기 표현을 학습하기 때문에, 신규 사용자나 sparse interaction 환경에서는 효과가 제한적일 수 있음. 이를 보완하기 위해 meta-learning, side information(예: 사용자 프로필, 시간 정보) 등 활용 필요
- CLSR의 fusion 모듈은 학습된 attention 가중치를 활용하지만, 이는 여전히 정적 구조에 의존하는 soft attention으로서 사용자별 동적 반응을 충분히 반영하지 못할 가능성이 있습니다.
5.2 결론
- 추천 시스템에서 표현 분리의 중요성을 실증적으로 입증
- 인과적 행동 요인 분리를 통해 추천의 해석력, 제어 가능성, 일반화 가능성 확보
- 자기 지도 학습 기반의 대조 학습을 통해 라벨 없이도 인과 표현 학습 가능성을 제시
- 상황 적응형 추천 구조를 통해 장단기 관심사의 비중을 문맥에 따라 조절할 수 있는 실질적 방안 제공
→ CLSR은 단순한 추천 정확도 향상을 넘어, 표현 학습 + 인과 추론 결합을 통한 추천의 구조적 개선 가능성을 보여줍니다.
마치며
CLSR은 2022년에 발표된 논문으로 주류 구조로 자리 잡은 모델은 아니지만, 장/단기 관심사를 명시적으로 분리하고, 자기 지도 학습 기반 대조 학습을 통해 이를 학습한다는 아이디어 자체로 의미 있어 보입니다. 특히 추천의 해석 가능성과 인과 구조에 관심이 있는 입장에서 보면, 표현 분리와 상황 적응형 융합이 인과 추론적 해석에 참고될 수 있습니다. 이제 해당 구조를 직접 구현해 보면서
- 장기/단기 표현이 실제로 인과적으로 잘 분리되는지
- 표현 간 교란(confounding)을 줄이기 위한 구조나 학습 전략이 효과적인지
- 반사실 시나리오 기반 실험을 통해 인과적 독립성이 검증 가능한지
- 표현을 인과 그래프 상의 요인으로 보고 do-intervention 또는 ATE 추정이 가능한지
등을 확인해 볼 예정입니다. 사용할 데이터셋으로는 음악 추천, 영화 추천, 뉴스 추천과 같이 사용자 행동의 시계열성과 맥락 변화가 뚜렷한 도메인을 중심으로 찾아보고 있습니다. 최종적으론 표현 분리 기반 추천 구조에 인과 추론 기법을 통합했을 때 어떤 새로운 해석력 또는 성능 개선 가능성이 있는지를 탐색해 보는 것이 이 리뷰 이후의 개인적인 목표입니다.



